About this Project:
This is the final project of (2022 Spring) Introduction of Artificial Intelligence. Our group has selected a NLP related topic - Fake News Detection, as our direction. We have utilized several Machine Learning and Deep Learning methods to evaluate the performance. And delightedly this project has won the Best Honorable Mention Award of this course.
這是 2022 Spring 所修陽明交大資工系所開設【人工智慧概論】的學期專案。開放自由擇題的前提下,我們組(四人)選擇嘗試 NLP 主題的假新聞檢測,採用機器學習與深度學習等不同方法做比對和檢驗。很榮幸該項目獲得這個課程的榮譽獎項- Best Honorable Mention Award.
[Github link: https://github.com/dianel0922/Final-Project]
Motivation and Goal
Motivation: Information spread on the media has proved to be swift and immediate, while its impacts are far-reaching. Thus, fake news can be damaging as we see in elections, Covid-19 and more.
Goal: Build a system that detects fake news through ML/DL techniques. It’s textual-based (given news headlines and content) and supervised-learning.
Methodology overview
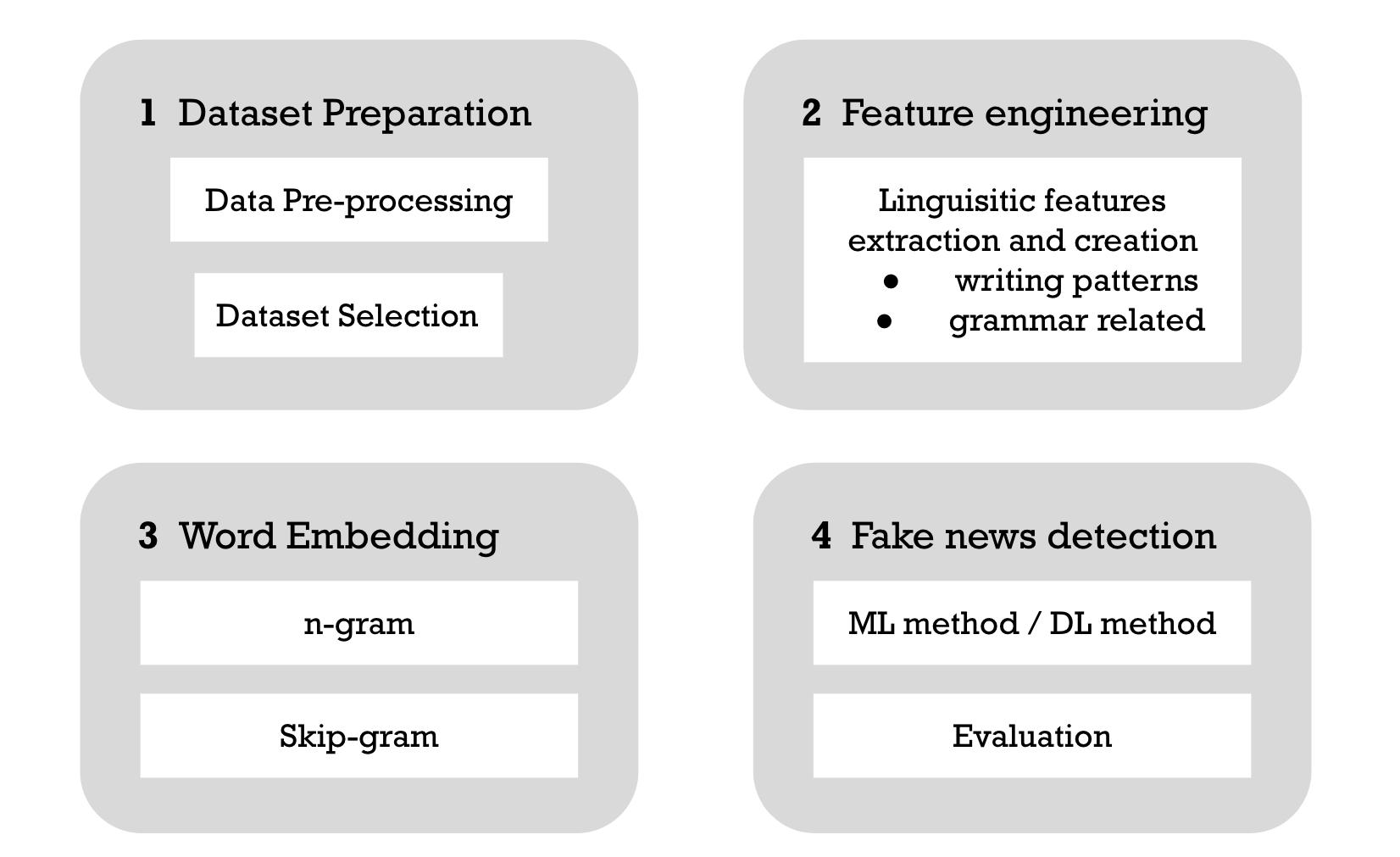
Dataset Selection: Welfake
There are all kinds of public fake news dataset, yet the qualities are diversed. We carefully chose a dataset that originated from Welfake. This dataset is a mixture of multiple open datasets, which is large enough in size after combination and have a balanced distribution.
Data Preprocessing
Just to name a few that are specific to this task:
- if one of (title, content) is missing, we copy that one to the other.
- we have used APIs to detect the languages, and make sure only English ones are left.
- we took away html noises, such as < br > and < p > etc.
Feature Engineering
We constructed two types of feature, which are present as follows:

Main Approach
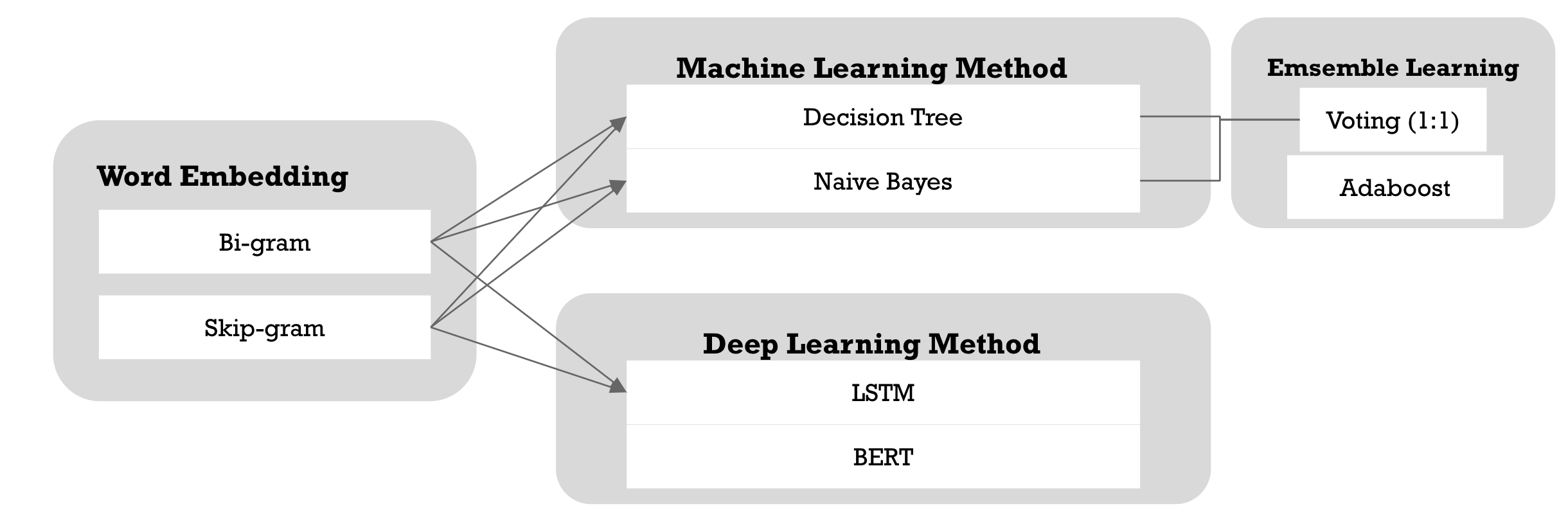
Baseline:
- skip-gram + news title/content + Naive Bayes for ML
- bi-gram + news title/content + LSTM for DL
Experiment Results:
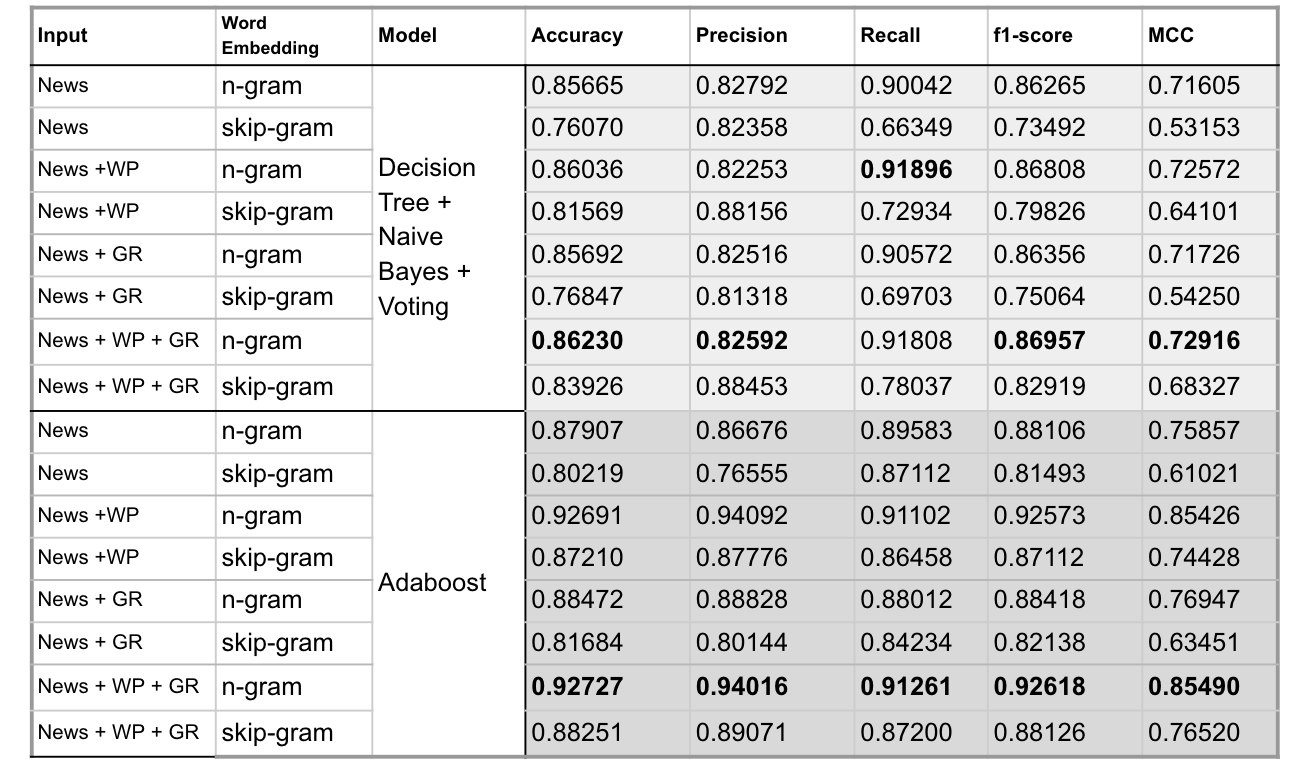
Input Configuration:
- News: news title and content
- WP: writting patterns features
- GR: Grammar related features
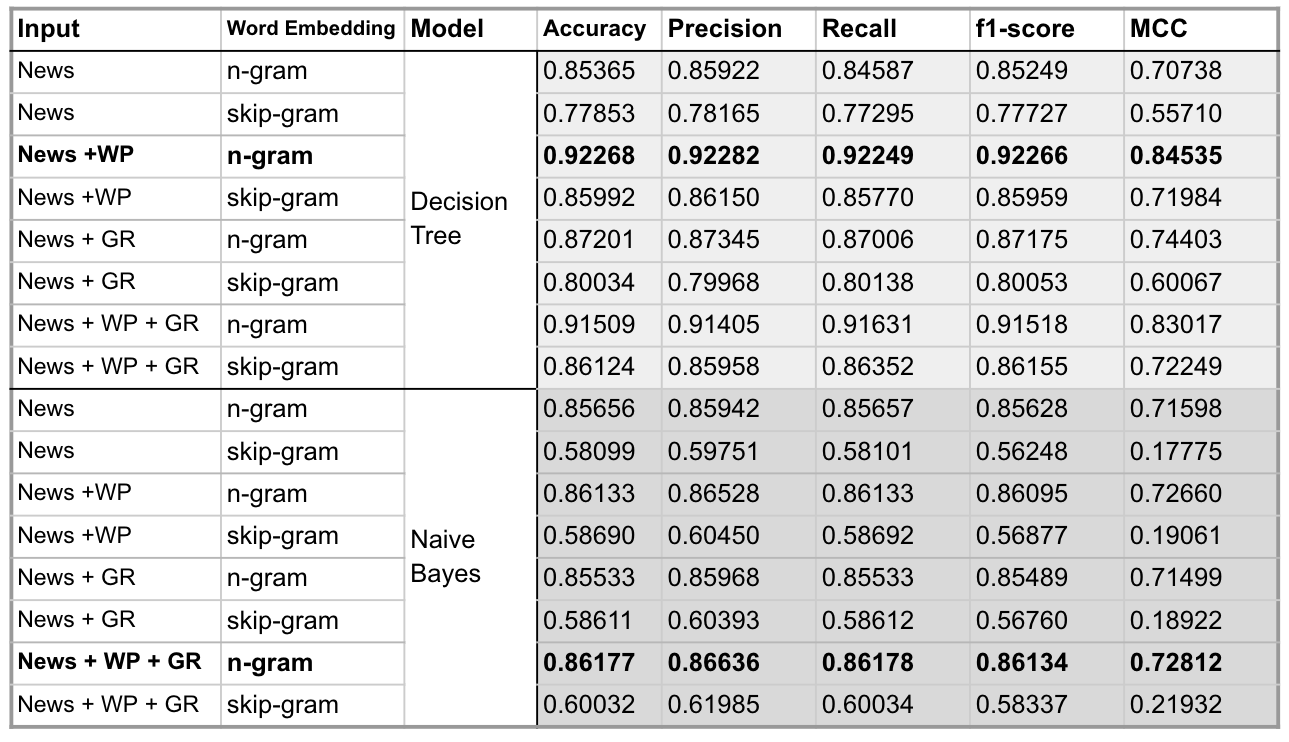
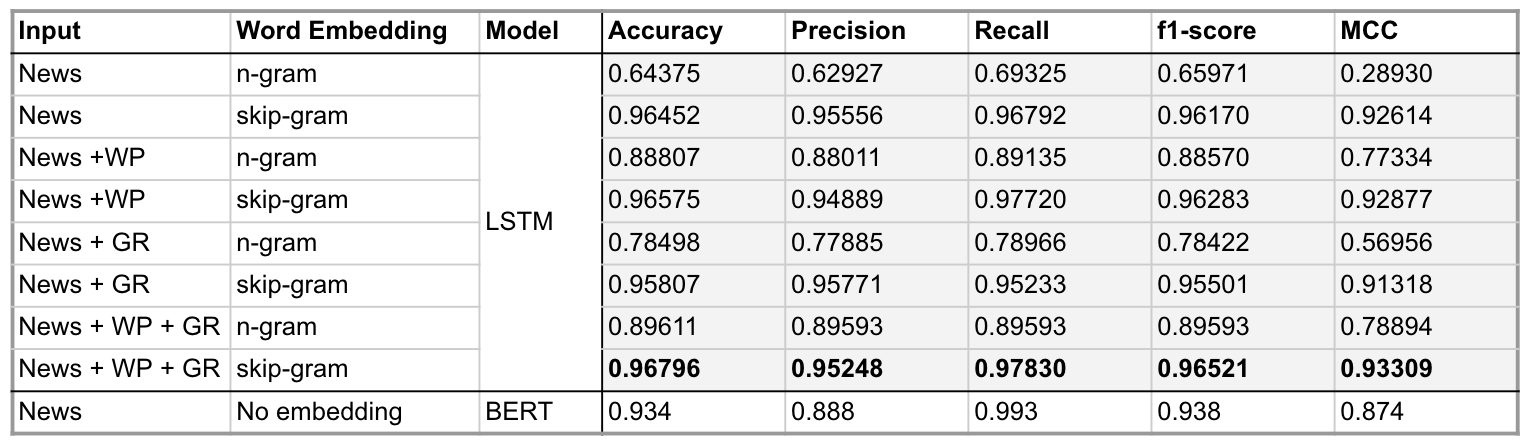
Simple Analysis and Evaluation:
- In all classifiers, using News + WP + GR as input (which means the input includes the preprocessed news title/content, writting patterns related features and Grammar patterns related features) and using skip-gram for word embedding, LSTM got the best accuracy(96.8%). 在所有Classifer中,以 News + WP + GR 為輸入,並用skip-gram進行word embedding的LSTM取得最好的ACC(96.8%)
- Having preprocessed news content/title as input only, BERT also scored well, with an accuracy of 93.4%; BERT 僅用前處理完的新聞input(新聞標題和內文),也能取得很好的ACC (93.4%)
- Decision Tree + Naive Bayes + Voting did not outperform other models, we thought that if we add more models and try more voting weights, will generate a better result. Decision Tree + Naive Bayes + Voting 的組合並沒有達到更好performance的預期,我們認為若如果有更多classifiers和更多權重的嘗試,效果可能會更好
- Since we balanced the dataset in advance in terms of true and fake news, the accuracy and f1-score did not have a big gap as expected. 由於資料集兩類的資料數量相當,在accuracy和F1-score之間的差異不大。
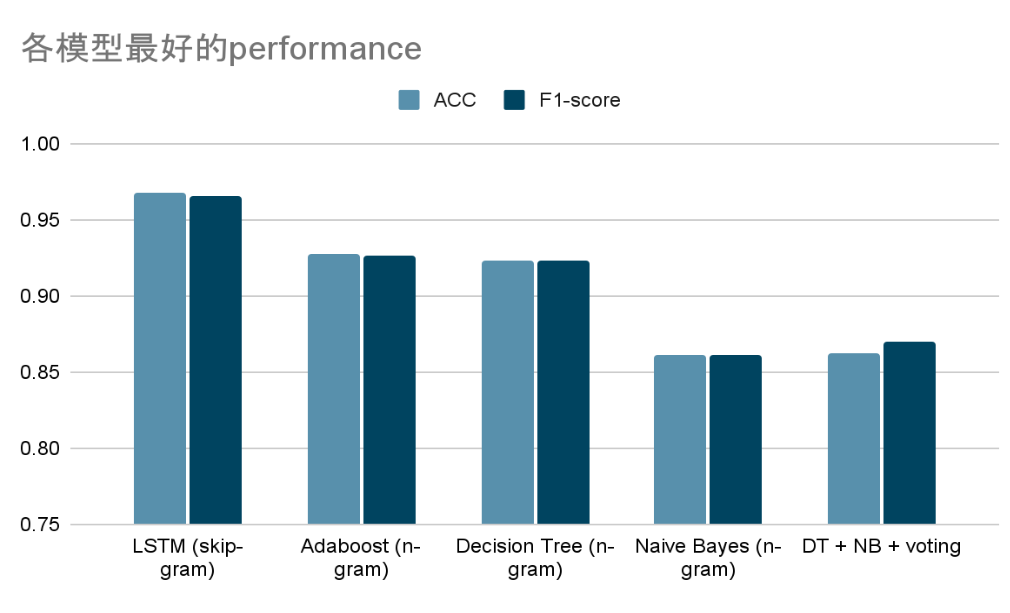
- Naive Bayes assumes that the probabilities are independent of each features, which does not hold often in reality, so the classification is less effective in cases where the correlation between features is large. Thus, we can see that naive bayes itself is not a very effective model under our setting, so the voting based upon using this method is not very good either. Naive Bayes 假設各種features之間的機率互相獨立,在現實中往往是不成立的,因此在feature之間相關性較大的情況下分類效果較差。由於上述提到的問題,可以看到naive bayes本身並不是一個效果很好的模型,因此使用此方法的voting效果也沒有達到很好。
- There is room to improve the robustness of our model. Perturbation or noises of any kind is not made to the data, which may be easily affected by the adversarial attack and thus affect the judgment of the model. (We have tried other datasets without pre-processed/raw data, the performance was slumped. But since this is not the focus of this project, we leave it for future discovery)模型的穩健度不夠,我們沒有對data做擾動或其它增加noise的方式,可能會輕易受到adversarial attack的影響從而影響模型的判斷結果。(我們有嘗試過其它dataset沒有經過前處理的原始資料,模型的performance都沒有很好。但這並不是這個項目的重點,因此我們暫時對這部分的處理)
- Differences on Word embedding: on LSTM, we load the word embedding matrices directly to the embedding layer; however, on other classifers, we need to take average out the word vectors to get a sentence vector (in order to represent each sentence, where we take 500 vectors of each, and pad 0 if missing).在LSTM的模型架構上,直接將詞向量矩陣加載到Embedding層中,但在classifier的地方,則需要將每個sentence中的詞向量(取500個,不足補0)取平均,得到sentence vector,因此效果不甚理想。
- on DL models,skip-gram is better in general
- on ML models,bi-gram is better in general
- 在判斷假新聞的過程中,可以看到分類器對於writing pattern作為判斷依據,比以grammer pattern為判斷依據,可以達到更佳的效果,我想可能是因為假新聞大部分都有某些操作的痕跡,所以我們從writing patterns判斷會比較可靠。
